Speech Shadowing App
I’ve recently completed a new application ( https://github.com/Dthurow/SpeechShadowing) to help language-learners practice speech shadowing. I decided to build this for my own use while learning Japanese. I’ve been practicing my reading, writing, and listening comprehension with various online tools (wanikani, anki, and Language Learning with Netflix), but realized I’d been neglecting an important aspect of learning a new language: speaking it. I currently don’t have any study buddies I can practice speaking with, and don’t want to spring for one on one tutoring just yet, so I found speech shadowing as something that could help me with my basic speech practice.
I had googled around for dedicated speech shadowing applications and couldn’t find any that were simply for speech shadowing and nothing else. And since I’m a programmer, I realized I could probably make an app for speech shadowing, and this project was born…
What is speech shadowing?
Speech shadowing is pretty simple. Take a snippet of audio in the target language you want to practice, listen to it repeatedly, then try recording yourself saying it, and compare the audio. The goal is to get an exact copy of the original audio’s pitch, timing, etc. This will help you when learning the new language by a) practice listening to the target language and parsing the sounds they’re saying, b) practice actually saying the unfamiliar words so you get better muscle memory and c) practice the correct pitch and accent for the target language.
Given this definition, you can see how you don’t need that many tools to do this. Most of the time online I got recommendations to use audio manipulation tools (e.g. Audacity) and audio recorders on my phone. But the audio recorder felt clunky to me since it wasn’t designed for listening to a short audio then repeating it and listening to your playback. And since splitting audio for speech shadowing was the only audio manipulation I wanted to do, learning Audacity or some other full-featured audio tool seemed like overkill.
I just wanted to take some target audio that was way too long for practicing (e.g. a podcast in japanese), and easily split it down into individual sentences and phrases, preferably without me needing to do anything other than click a “split audio” button.
What the app does
With this app I wanted a simple application that does speech shadowing and nothing else.
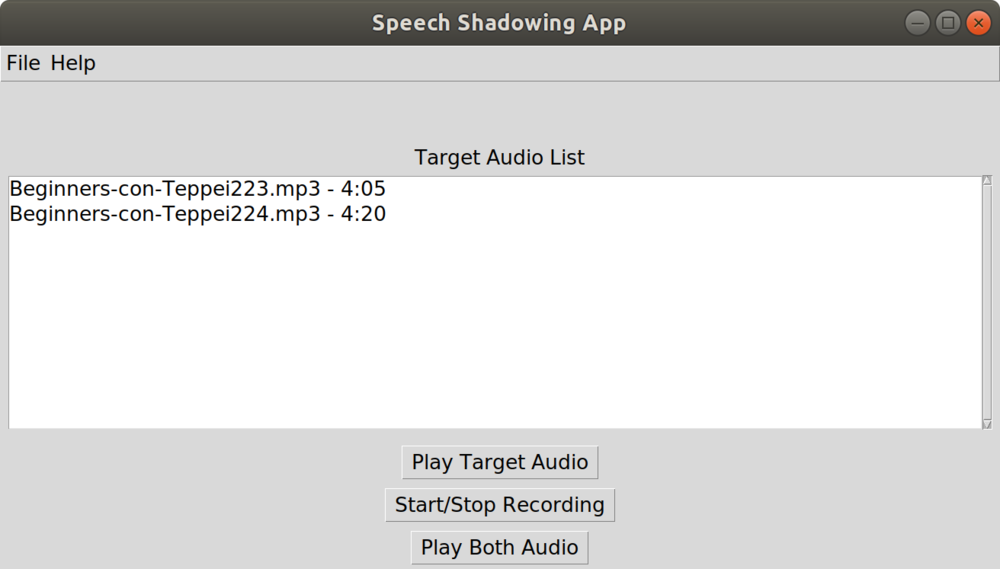
As you can see, it’s a simple and not-pretty design, but it works! The main box lists all target audio currently uploaded into the app, along with the length of the audio clip. There are three buttons on the main page: play the target audio, start and stop recording, and play both target and recorded audio, one after each other. From my short time working on speech shadowing, that’s pretty much all I needed to practice. Click on the target audio, listen to it repeatedly with the “Play Target Audio” button, record yourself, and then listen to both audio back to back, to listen for differences.
Some versions of speech shadowing I came across involve recording yourself as the target audio plays, then listening to both target and your version simultaneously. I found this way wasn’t useful to me, because I couldn’t fully hear myself when I was speaking or listening to the recordings afterwards. I also wasn’t remembering what the audio was saying. Practicing solely pitch accent, this makes sense, but I wanted to be able to parse the sounds as well.
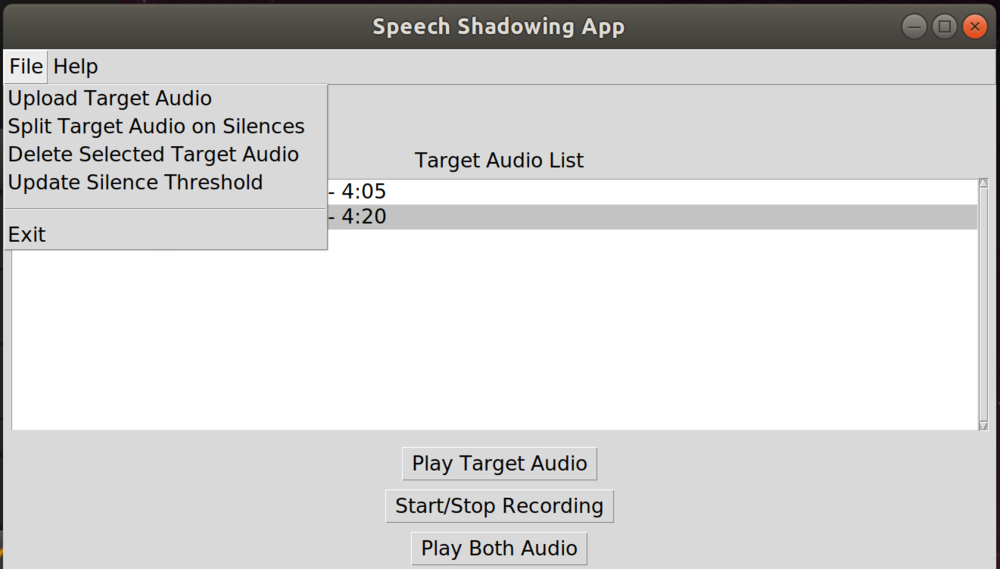
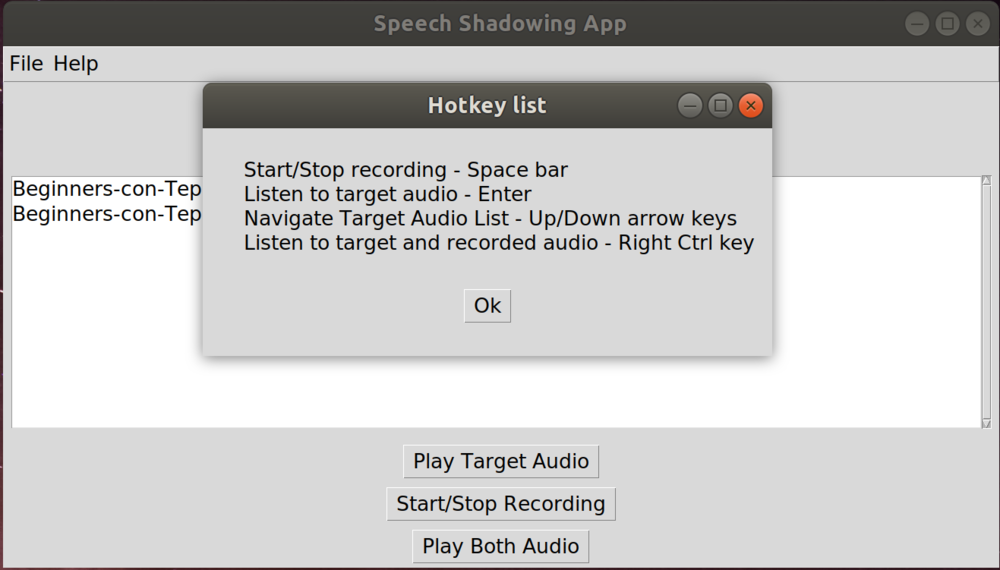
The “File” menu button gives some basic file management options, uploading more target audio or deleting the selected target audio. The “Help” menu button opens up a browser with a more in-depth help and how-tos. I also provide a hotkeys cheat sheet page, since I always like using hotkeys over clicking buttons with a mouse if I can.
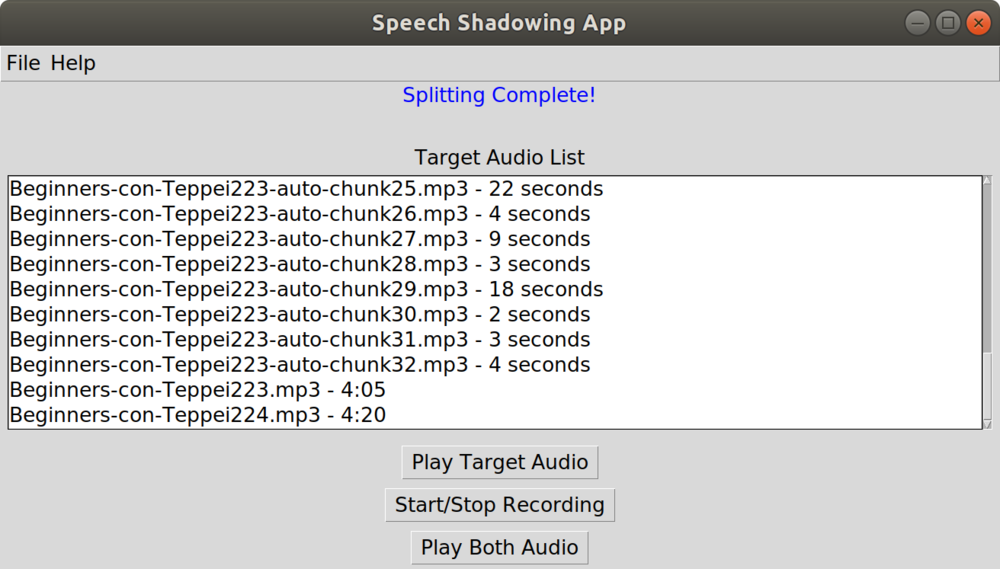
Probably the most helpful feature is the “Split Target Audio on Silences” button under the “File” menu. This takes the selected target audio, identifies silences of longer than a second, then splits the target audio out and saves the individual audio chunks. This allows users to upload longer target audio and split it into individual sentences or phrases. I had been having difficulty with collecting target audio to practice speech shadowing and found this functionality useful. Most of the audio I had found was either purposefully slowed-down sentences for learning, or native speed audio that was long-form that I had to split manually using unfamiliar tools like Audacity. I wanted a button I could click that would make audio snippets of sentences and phrases from native language speakers, and since I’m a programmer, I made that button! I used the podcast Nihongo Con Teppei for beginners ( https://nihongoconteppei.com) for testing, and found the right settings to get a pretty good first-cut level split on silence. It’s not perfect by any means, but it’s much easier and faster than doing it manually myself, and getting rid of hurdles to practicing a language is half the battle!
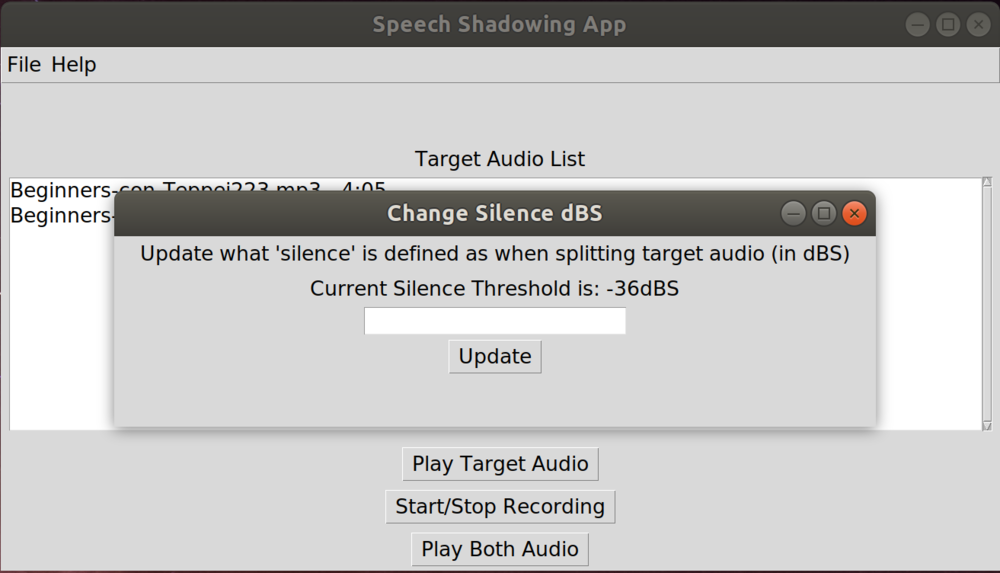
Probably what affects a proper split the most is what you define as “silence” in the audio. For my testing, the podcast had music in the background, so it wasn’t completely silent. I had to tweak the dBS that I defined as “silence” quite a bit before I got a good cut. Eventually I’d like to have it auto-guess what’s the best dBS for a given audio clip, but for now, I just added the ability to manually set what you think the correct value would be. The default setting is -36dBS. If you attempt to split a target audio, and it splits too often, change it to a more negative number (e.g. -50). If you attempt to split target audio and it doesn’t split the audio enough, make it a less negative number (e.g. -20).
Conclusion
I’ve started using this app for the last couple weeks and it seems to work well for what I need. I’ll most likely continue to update and tweak it as I find new functionality that I realize I need. Hopefully this will be useful to other language learners as well.
I’ll be writing a second post focused on the technical side of things, so keep an eye out for that.